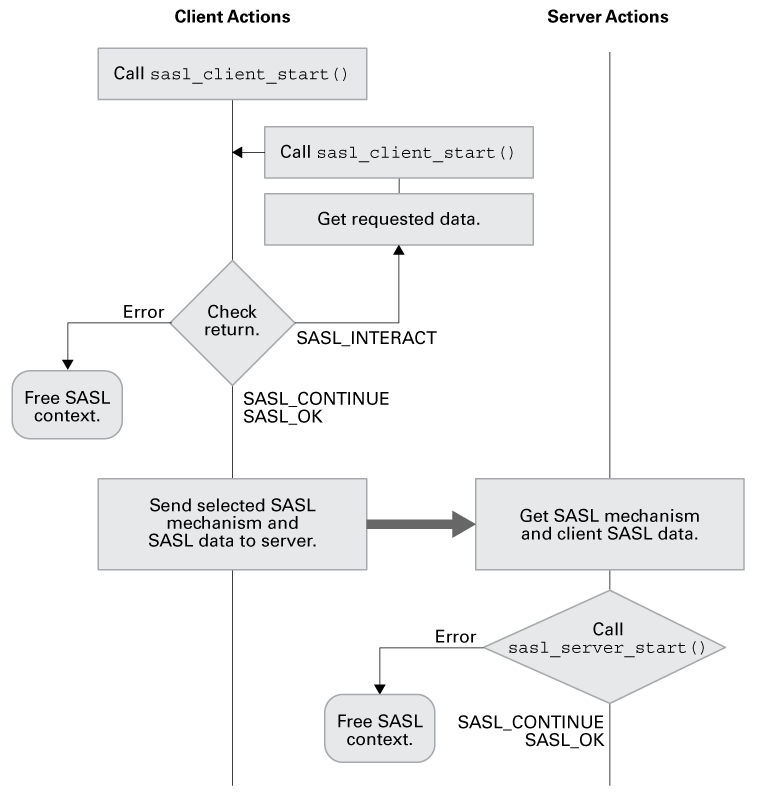
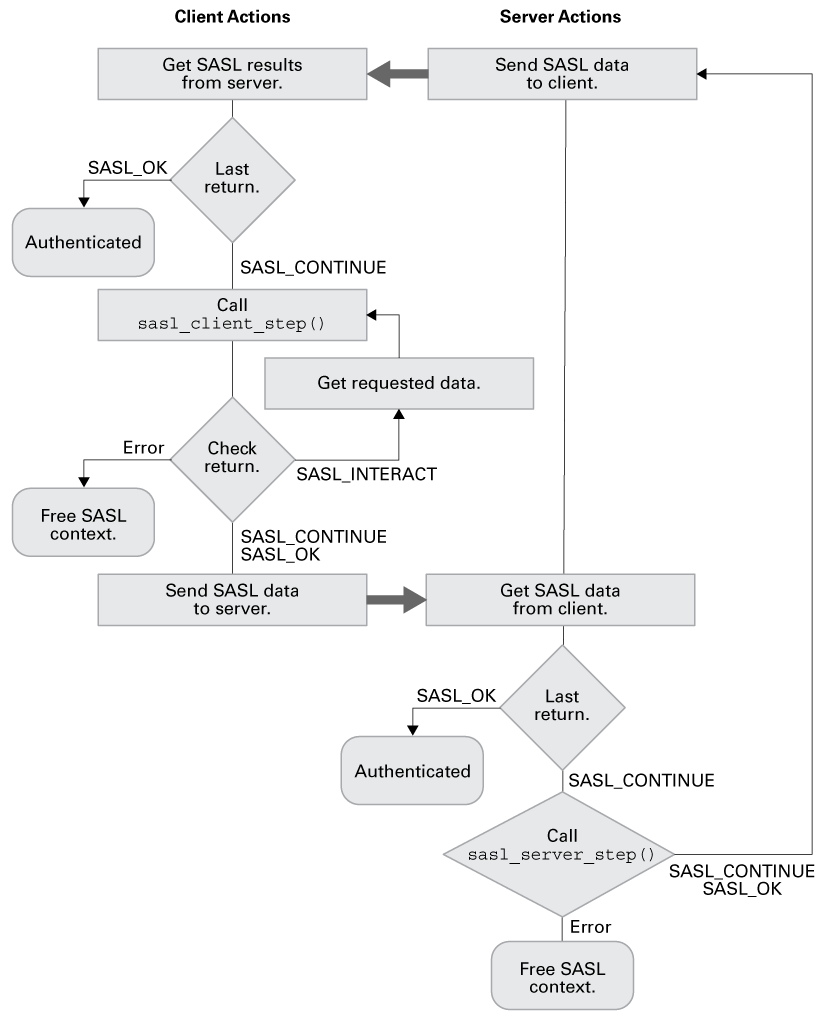
The Things Stack是企业级的 LoRaWAN 网络服务器,建立在开源核心之上。Things Stack允许您在自己的硬件或云上构建和管理 LoRaWAN 网络。
TTS 是 The Things Stack, LoRaWAN Network Server Stack。Things Stack 目前是网络服务器实现的版本3,因此也被非正式地称为V3。
TTN 是 “物联网”(The Things Network),它是一个全球协同物联网生态系统,使用 LoRaWAN 创建网络、设备和解决方案。The Things Network 运行着 The Things Stack Community Edition,这是一个众包、开放和去中心化的 LoRaWAN 网络。这个网络是一个很好的开始测试设备、应用程序和集成,并熟悉 LoRaWAN 的方法。
TTI 是 The Things Industries:该公司主要负责The Things Stack 的开发和文档编写。Things Industries 还提供具有额外企业功能的云托管和本地私有 LoRaWAN 网络,以及针对企业客户的高级支持计划。
Command-Line Interface
…
Console
控制台是 LoRaWAN 的 Things Stack 的管理应用程序。它是一个 Web 应用程序,可以用来注册应用程序,终端设备或网关,监控网络流量,或配置网络相关选项等。
API
Gateway Server MQTT
MQTT 协议可用于开发自定义包转发器或网关桥接器,用于在网关和 The Things Stack 之间交换流量,或用于测试目的,方便地模拟网关流量。它是一个替代 Basic Station 和 Semtech UDP协议。
用户可以处于多个状态之一:请求、批准、拒绝、挂起等。用户的状态决定了用户是否能够执行操作,以及哪些操作。正常情况下,用户处于“批准”状态。如果 The Things Stack 被配置为需要新用户的管理批准,那么用户最初处于“请求”状态,管理用户可以将其更新为“批准”或“拒绝”状态。如果用户行为不当,也可能被管理员挂起。
Gateways
网关可以通过选择一个ID和可选地注册网关的EUI来注册。注册后,可以创建一个API密钥;网关可以使用它的ID(或EUI)和API密钥一起使用 The Things Stack 进行身份验证。
The Things Stack supports discovering services using DNS SRV records. This is useful when dialing a cluster only by host name; the supported services and target host name and port are discovered using DNS.
To support service discovery for your The Things Stack cluster, configure DNS SRV records with the following services and protocols:
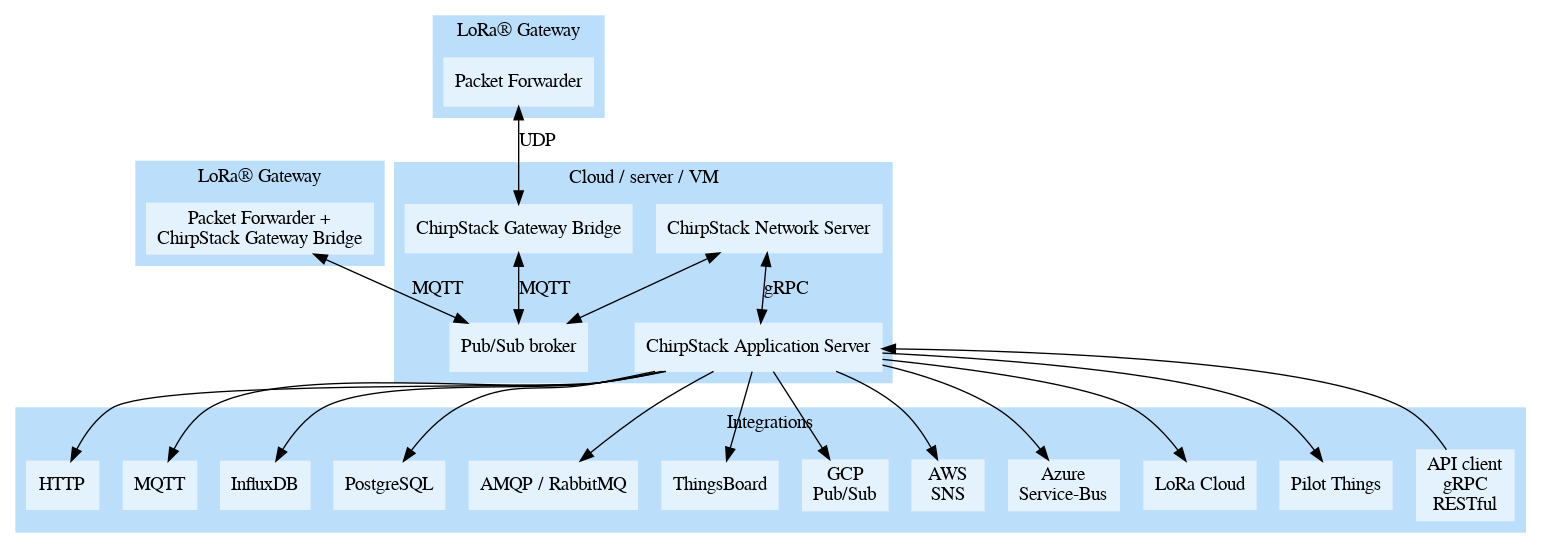
ChirpStack Application Server 处理应用程序有效负载的加密和解密。它还保存每个设备的应用程序键,并在 OTAA 激活时处理 join-accept。这意味着有效载荷将被解密发送到集成,但在有效载荷被发送到 ChirpStack 网络服务器之前,网络服务器无法访问这些有效载荷。
Web 界面
ChirpStack Application Server 提供了一个 Web 界面 (构建在提供的 RESTful API 之上)。这个 Web 界面可以用来管理用户、组织、应用程序和设备。
用户授权
使用 ChirpStack Application Server,可以授予用户全局的管理员权限,使他们成为组织的管理员,或者为他们分配组织内的仅查看权限。这使得在多租户环境中运行 ChirpStack Application Server 成为可能,在这种环境中,每个组织或团队只能访问他们自己的应用程序和设备。
API
为了与外部服务集成,ChirpStack Application Server 提供了gRPC 和 RESTFul API,公开了与 Web 界面相同的功能。
有效载荷和设备事件
ChirpStack Application Server 提供了不同的方式发送和接收设备负载(例如MQTT, HTTP, InfluxDB,…)。
注意:下行负载也可以通过API进行调度。
网关发现
对于包含多个网关的网络,ChirpStack Application Server 提供了一个特性来测试网关的网络覆盖。通过向每个网关定期发送 “ping”,ChirpStack 应用服务器能够发现这些 ping 被同一网络中的其他网关接收的情况。采集到的数据以地图的形式显示在 Web 界面上。可以为每个 Network Server 启用和配置此功能。
SET foo bar HSET person:1 name "Rick Sanchez" age 70 HSET person:2 name "Morty Smith" age 14 HSET person:3 name "Summer Smith" age 17 HSET person:4 name "Beth Smith" age 35 HSET person:5 name "Shrimply Pibbles" age 87
Distributed Processing
当 RedisGears 在集群中运行时,默认情况下它将在集群的所有分片上执行函数。通过向 run ()操作提供 collect = False 参数来禁用。
def maximum(a, x): ''' Returns the maximum ''' a = a if a else 0 # initialize the accumulator return max(a, x)
# Original, non-reduced, maximum function version gb = GearsBuilder() gb.map(lambda x: int(x['value']['age'])) gb.accumulate(maximum) gb.run('person:*')
--help prints this usage text -e <value> | --endpoint <value> Kafka Connect REST URL, default is http://localhost:8083/ -f <value> | --format <value> Format of the config, default is PROPERTIES. Valid options are 'properties' and 'json'. Command: ps list active connectors names. Command: get get the configuration of the specified connector. Command: rm remove the specified connector. Command: create create the specified connector with the config from stdin; the connector cannot already exist. Command: run create or update the specified connector with the config from stdin. Command: diff diff the specified connector with the config from stdin. Command: status get connector and it's task(s) state(s). Command: plugins list the available connector class plugins on the classpath. Command: describe list the configurations for a connector class plugin on the classpath. Command: pause pause the specified connector. Command: restart restart the specified connector. Command: resume resume the specified connector. Command: validate validate the connector config from stdin against a connector class plugin on the classpath. Command: task_ps list the tasks belonging to a connector. Command: task_status get the status of a connector task. Command: task_restart restart the specified connector task.
# This is a basic workflow to help you get started with Actions
name:CI
# Controls when the action will run. on: # Triggers the workflow on push or pull request events but only for the master branch push: branches: [ master ] pull_request: branches: [ master ]
jobs: build: runs-on:ubuntu-latest name:Ajobtodeployblog. steps: -name:Checkout uses:actions/checkout@v1 with: submodules:true# Checkout private submodules(themes or something else). # Caching dependencies to speed up workflows. (GitHub will remove any cache entries that have not been accessed in over 7 days.) -name:Cachenodemodules uses:actions/cache@v1 id:cache with: path:node_modules key:${{runner.os}}-node-${{hashFiles('**/package-lock.json')}} restore-keys:| ${{runner.os}}-node- -name:InstallDependencies if:steps.cache.outputs.cache-hit!='true' run:npmci # Deploy hexo blog website. -name:HexoAction id:deploy uses:sma11black/hexo-action@v1.0.4 with: deploy_key:${{secrets.DEPLOY_KEY}} user_name:shankai user_email:shankai.kvn@gmail.com commit_msg:${{github.event.head_commit.message}}# (or delete this input setting to use hexo default settings) # Use the output from the `deploy` step(use for test action) -name:Gettheoutput run:| echo"${{ steps.deploy.outputs.notify }}"
fatal: could not read Username for'https://github.com': No such device or address FATAL Something's wrong. Maybe you can find the solution here: https://hexo.io/docs/troubleshooting.html Error: Spawn failed at ChildProcess.<anonymous> (/github/workspace/node_modules/hexo-deployer-git/node_modules/hexo-util/lib/spawn.js:51:21) at ChildProcess.emit (events.js:314:20) at Process.ChildProcess._handle.onexit (internal/child_process.js:276:12)